
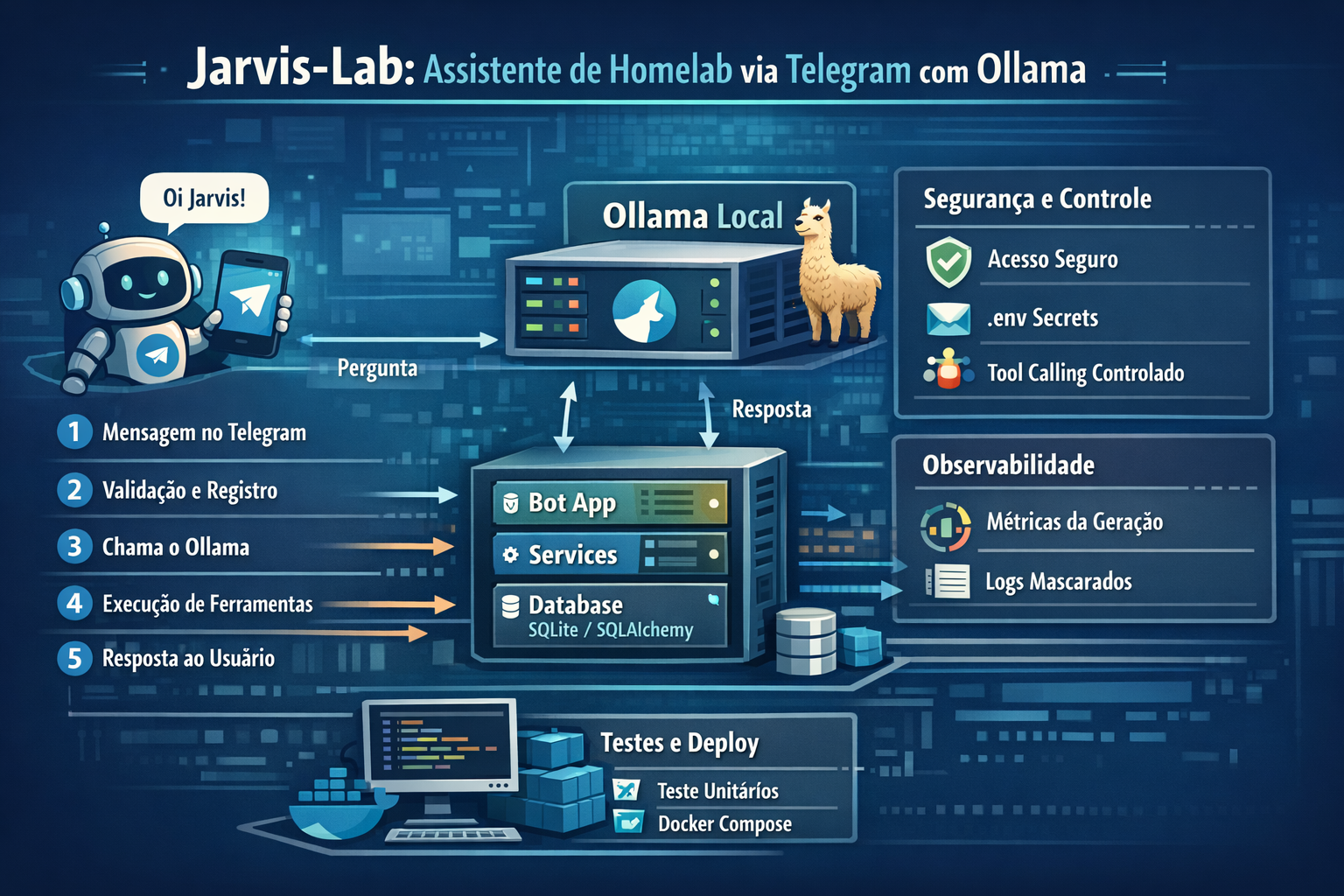
O Jarvis-Lab é um projeto em Python que conecta o Telegram ao meu homelab usando Ollama como camada de interpretação de linguagem natural. A ideia central é simples: enviar uma mensagem pelo Telegram, interpretar essa mensagem com um modelo local e responder a partir de uma camada de backend controlada.
O objetivo não é apenas conversar com um modelo. O foco é criar uma interface prática para consultar o ambiente, acionar ferramentas internas e manter controle sobre custos, latência e segurança.
Arquitetura atual#
A arquitetura foi separada em blocos pequenos:
- app/bot/ recebe mensagens e concentra a integração com o Telegram.
- app/services/ faz a orquestração da mensagem, integra com o Ollama e executa ferramentas.
- app/database/ isola modelos, conexão e persistência com SQLAlchemy.
- tests/unit/ cobre as partes principais com testes unitários.
Hoje o fluxo principal é:
- O usuário envia uma mensagem no Telegram.
- O bot valida se o chat está autorizado.
- A mensagem é salva no banco.
- O backend chama o Ollama.
- Se o modelo pedir uma ferramenta, o backend executa essa ferramenta e faz uma segunda chamada ao modelo.
- A resposta final é enviada ao Telegram.
Decisões tomadas#
Algumas decisões foram intencionais desde o início.
Python e arquitetura assíncrona#
O projeto usa Python com asyncio porque a integração com Telegram, HTTP e banco é naturalmente I/O bound. Isso reduz bloqueios desnecessários e simplifica o fluxo do bot.
Ollama local#
O Ollama foi escolhido para manter o processamento dentro do homelab. Isso melhora a privacidade, reduz a dependência de provedores externos e facilita testes com modelos diferentes.
SQLite com caminho para Postgres#
O banco inicial é SQLite para manter a operação simples. Ao mesmo tempo, a persistência foi desenhada com SQLAlchemy para facilitar a migração futura para PostgreSQL sem reescrever a camada de acesso a dados.
Segredos em .env#
Toda configuração sensível fica em .env, incluindo token do Telegram, modelo e URL do Ollama. Isso evita espalhar configuração no código e simplifica deploy local.
Observabilidade por mensagem#
Uma decisão importante foi salvar métricas de geração do Ollama ligadas a cada mensagem. Agora o projeto registra tokens de prompt, tokens de resposta, tokens por segundo, durações e o payload bruto da geração. Isso permite medir quanto cada mensagem realmente custou em processamento.
Tool calling controlado#
O modelo não executa nada diretamente. Ele apenas sugere o uso de ferramentas, e o backend decide o que realmente pode ser executado. Isso reduz risco e deixa a camada de automação mais previsível.
O que ja esta funcionando#
- Integração com Telegram via polling
- Controle de acesso porchat_id
- Integração com Ollama por HTTP
- Persistência de usuários e mensagens
- Persistência de métricas de geração por mensagem
- Testes unitários para bot, serviços e repositório
- Mascaramento do token do Telegram nos logs
Próximos passos#
Os próximos passos mais relevantes sao:
- Adicionar migração de banco para evitar recriar o SQLite a cada mudança de schema
- Expandir o conjunto de ferramentas do homelab com foco em consultas seguras
- Melhorar a observabilidade com consultas agregadas por usuário, mensagem e modelo
- Adicionar endpoint de healthcheck e empacotamento com Docker Compose